system tables within a Unity Catalog-enabled workspace. Vantage requires only the Data Reader permission to access these system tables and does not have the ability to perform any write actions or administrative changes in your Databricks account.
You can perform the Databricks integration for each Databricks account you have or each region your Databricks account uses. Each integration you perform will collect data for all the workspaces within your Databricks account that are deployed within the same region.
Usage data is available for services that measure consumption, such as usage in DBUs (Databricks Units) or GBs.
Databricks System Tables
System tables are a set of Unity Catalog tables that expose operational and billing metadata. For cost monitoring, Vantage uses the following tables:system.billing.usage: contains SKU-level usage data by workspace.system.billing.list_prices: provides SKU-level list pricing.system.billing.account_prices: shows discounted prices for customers on enterprise agreements.
This table is considered to be in Private Preview through Databricks and may require you to work with your Databricks account team to enable it.
If Databricks costs in Vantage appear to reflect list pricing rather than your negotiated enterprise rates, verify that
system.billing.account_prices is enabled and backfilled in your Databricks account. After this table is available, subsequent ingestions use discounted pricing. Historical cost data that was imported before account_prices was available is not automatically updated. Contact support@vantage.sh to request a re-import of prior periods.system.compute.clusters: contains metadata, like human-readable names, for clusters and custom tagging.system.compute.warehouses: contains metadata such as warehouse configuration, human-readable warehouse names, and custom tags.system.access.workspaces_latest: contains human-readable names for workspaces.
If you are migrating from the v1 Databricks integration, see How to Migrate from the v1 Integration to v2 before creating a new connection.
Connect Your Databricks Account
You can connect to Databricks either manually using the below workflow or using a Terraform module.The Serverless SQL Warehouse required for the integration will incur a cost, estimated at approximately $84/month. Vantage uses the smallest possible Serverless SQL Warehouse to keep these costs minimal.
Prerequisites
- You must have a Vantage Organization Owner or Integration Owner role to add or remove this integration. See the Role-Based Access Control documentation for details.
- You need account admin privileges in Databricks.
- A Unity Catalog-enabled workspace.
- Review this page from the Databricks documentation for additional information about permissions with Unity Catalog.
- Create a free Vantage account, then follow the steps below to integrate Databricks costs.
Vantage will use the following IP addresses when connecting to your Databricks account.
Create the Connection
To integrate your Databricks account with Vantage, follow the below steps:Collect your workspace and account credentials
Create a service principal
Create a serverless SQL warehouse and grant the service principal Can Use permissions on the warehouse
Grant the service principal Data Reader permissions on the system tables
Add resource IDs and account credentials to the Vantage integration form
Step 1 - Collect Credentials and Open Workspace
1
Log in to the Databricks console.
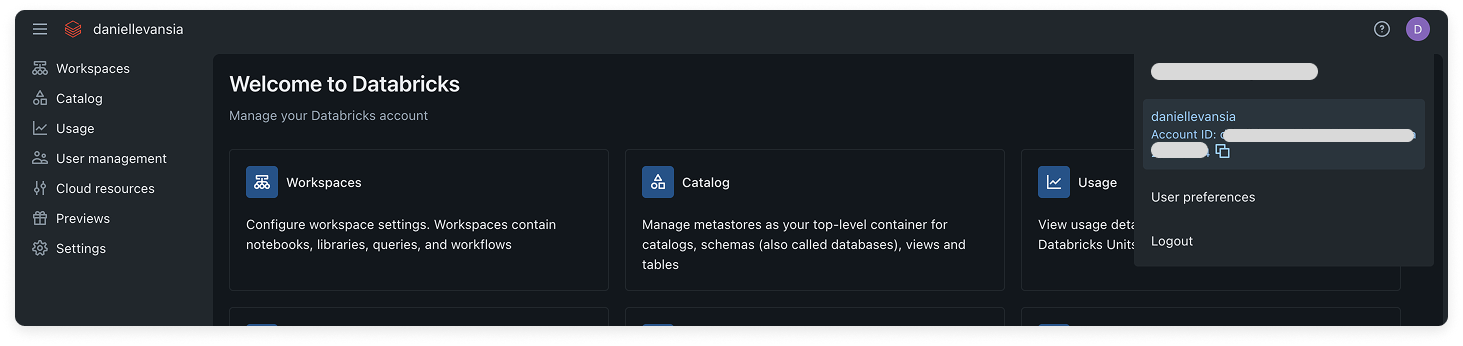
2
From the top right of the console, click your avatar and copy your Databricks Account ID for later use.
Click to view example image
Click to view example image
3
Click Workspaces, then select a Unity Catalog-enabled workspace within your Databricks account.
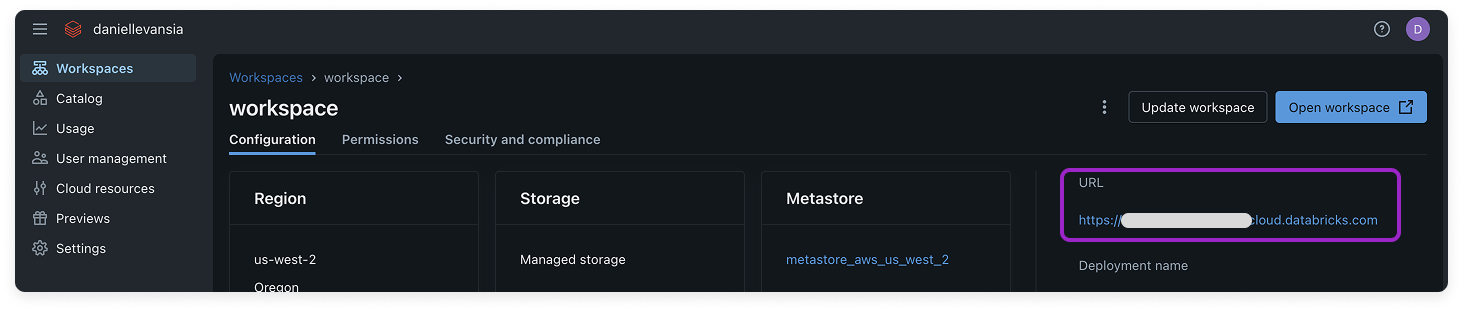
4
Copy your Workspace URL for later use. Then, open the workspace.
Click to view example image
Click to view example image
Step 2 - Create a Service Principal
1
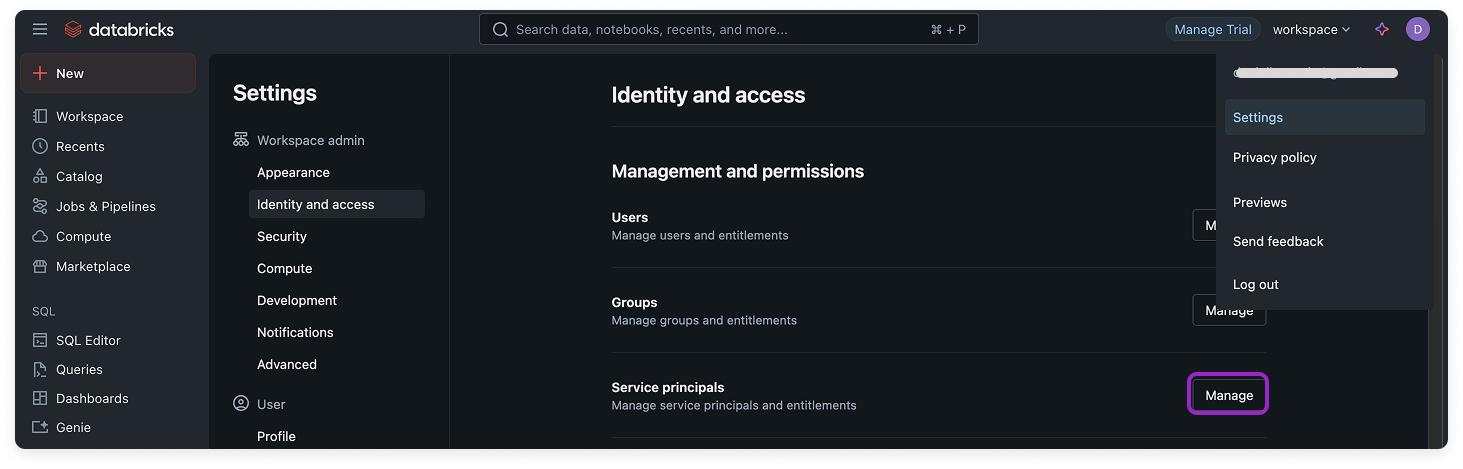
From the top right of the workspace, click your avatar and select Settings.
2
On the Settings screen, under Workspace admin, select Identity and access.
3
Next to Service principals, click Manage.
Click to view example image
Click to view example image
4
Click Add service principal.
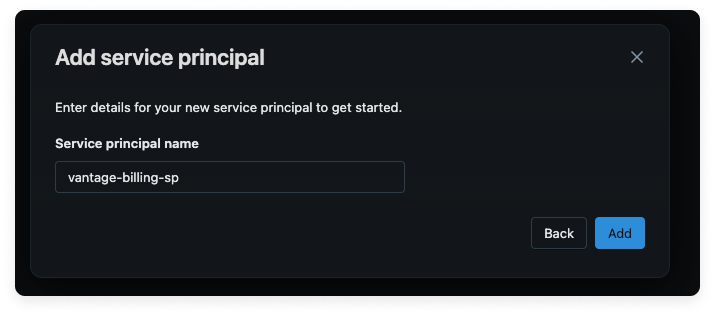
- On the Add new service principal modal, click Add new.
- For Service principal name, enter vantage-billing-sp.
- Click Add.
Click to view example image
Click to view example image
5
Open the newly created service principal, then select the Secrets tab.
6
Click Generate secret.
7
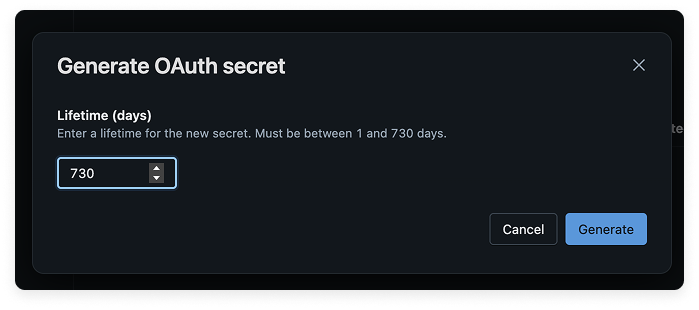
Enter a secret Lifetime of 730 days, then click Generate. (When the secret expires, you’ll need to create a new one and reconfigure the integration in Vantage with the corresponding secret and client ID.)
Click to view example image
Click to view example image
8
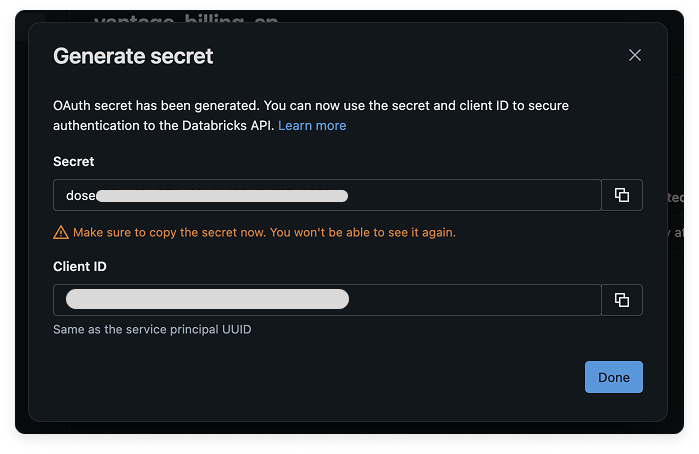
Your Secret and Client ID are displayed. Copy these values for later use.
Click to view example image
Click to view example image
Step 3 - Create a Serverless SQL Warehouse and Assign Permissions
1
From the left navigation menu, under SQL, click SQL Warehouses.
2
Click Create SQL warehouse, and enter the following information:
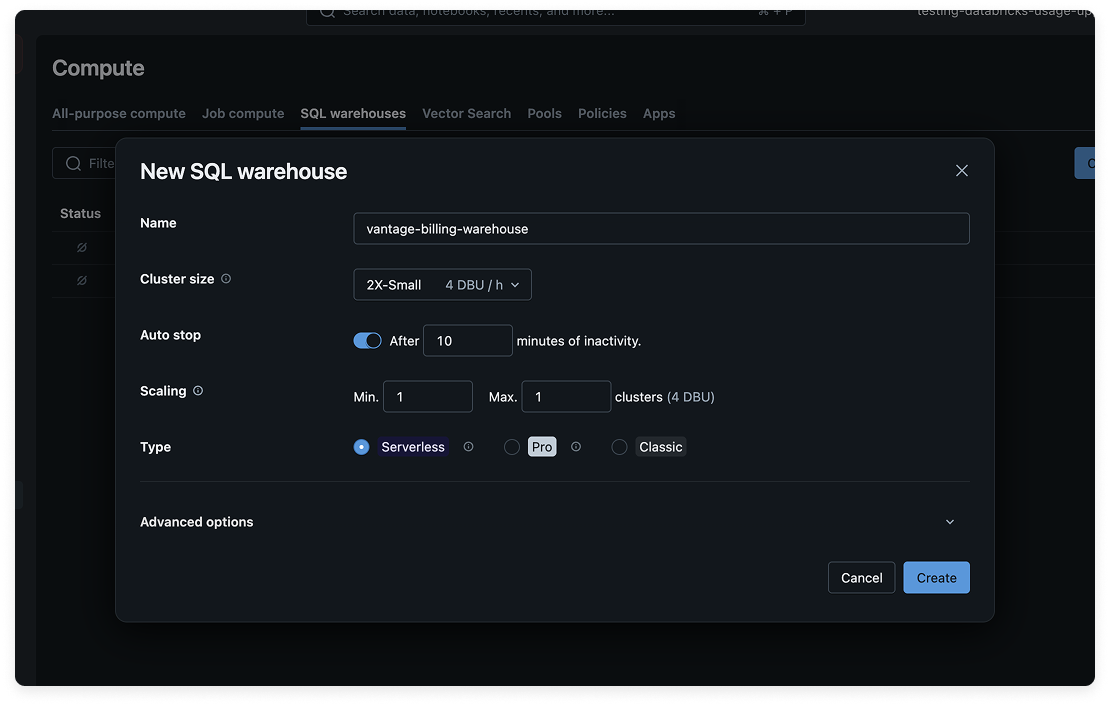
- For Name, enter vantage-billing-warehouse.
- For Cluster size, select 2X-Small.
- For Type, select Serverless.
Click to view example image
Click to view example image
3
Click Create.
4
After the warehouse is created, the Manage permissions modal window is displayed. (To access this modal, you can also click Permissions on the top right of the screen.)
5
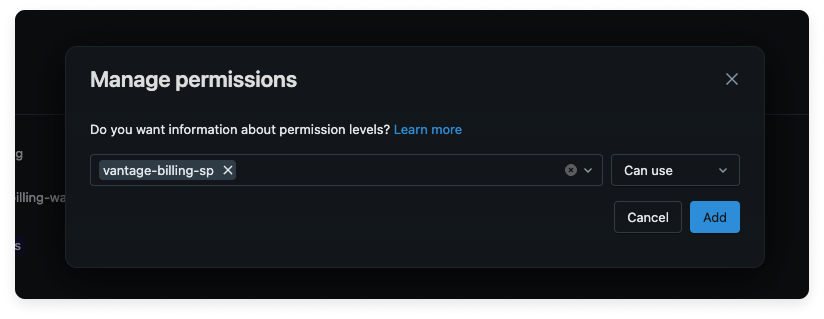
Search for and select the vantage-billing-sp service principal.
6
Select the Can Use permission and click Add.
Click to view example image
Click to view example image
7
Close the Manage permissions modal and copy your warehouse ID, displayed next to the warehouse name, for later use.
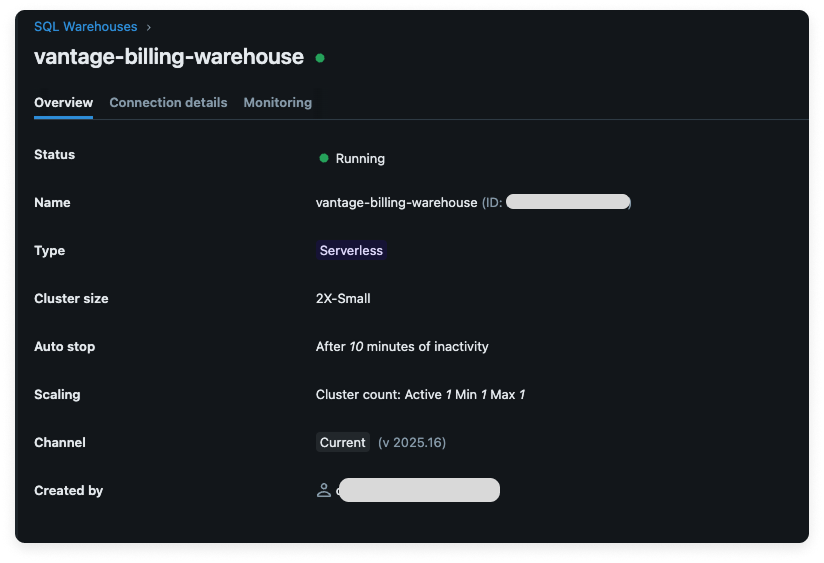
Click to view example image
Click to view example image
Step 4 - Grant Data Reader Permissions to the Service Principal
1
From the top of the left navigation menu, click Catalog.
2
In the Catalog menu, expand My Organization > system.
3
Select the
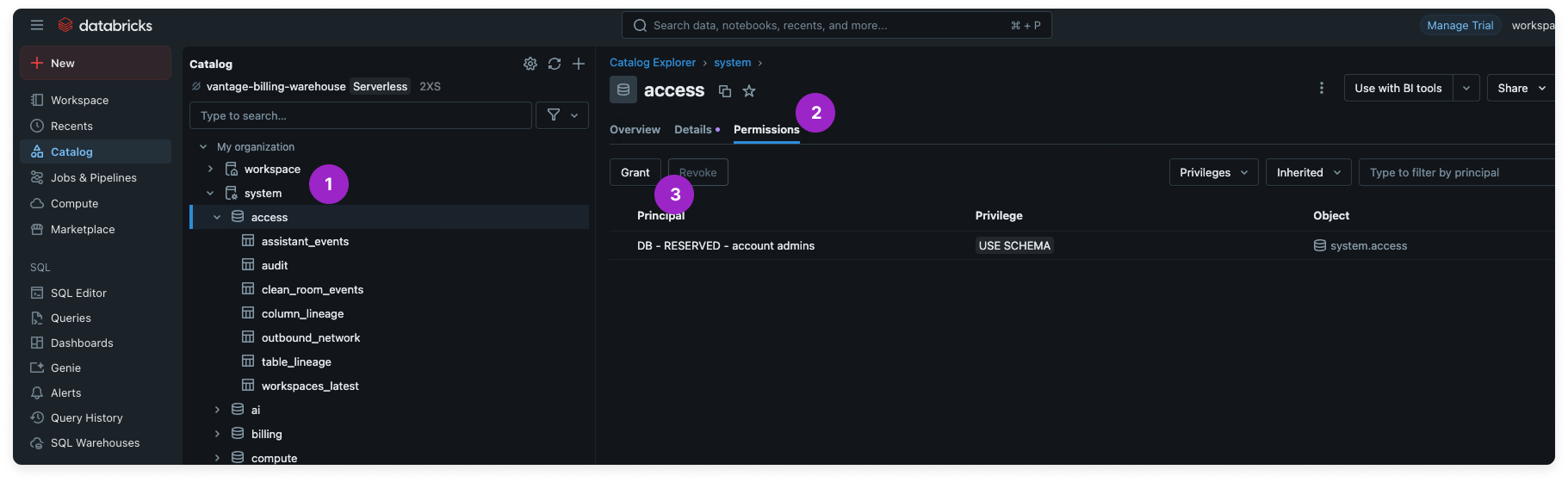
access schema. On the right, click Permissions > Grant.Click to view example image
Click to view example image
4
Enter the following information to create a grant on
system.access:- For Principals, select the vantage-billing-sp service principal.
- For Privilege presets, select Data Reader.
5
Click Confirm.
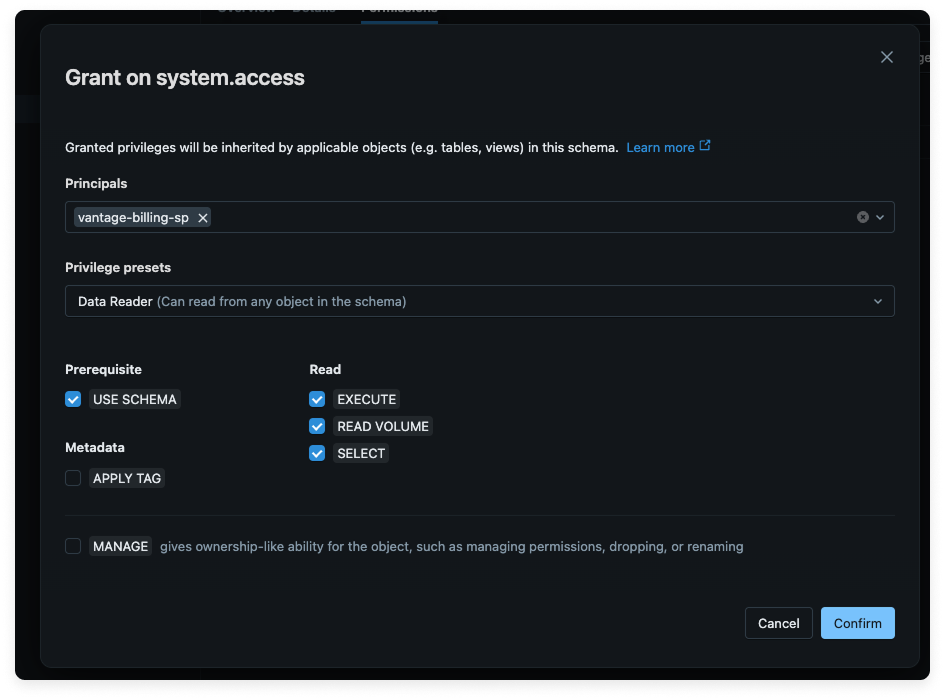
Click to view example image
Click to view example image
6
Repeat the last two steps and grant Data Reader permissions for the
billing and compute schemas.Step 5 - Add Credentials to Vantage
1
From the Vantage console, navigate to the Databricks Settings page.
2
Click the Connect tab, then click Set Up Account.
3
On the Integration modal screen, enter the following information:
- For Databricks Account ID, enter your account ID that you obtained in step 1.
- For Service Principal OAuth Client ID and Service Principal OAuth Client Secret, add the ID and secret you obtained in step 2.
- For Workspace URL, add the URL you obtained in step 1.
- For SQL Warehouse ID, add the warehouse ID you obtained in step 3.
4
Click Connect Account.
As soon as costs are processed, they will be available on your All Resources Cost Report. If you decide to remove your Databricks integration from Vantage, all costs associated with your Databricks account will be removed from the Vantage console.
Connect via Terraform
You can also connect your Databricks account using theterraform-databricks-vantage-integration module. Follow the steps in the module’s README to connect your account.
Next Steps - Manage Workspace Access
Once the import is complete and the integration status changes to Stable, you can select which workspaces this integration is associated with. See the Workspaces documentation for information.Migrate to the New Databricks Billing Integration
This section provides information about v1 and v2 of the Databricks integration in Vantage.What’s Improved in the New Integration
Previously, Vantage ingested Databricks costs using Databricks billable usage logs (integration released in December 2022). These logs provided SKU-level usage but reflected only list pricing, and enterprise customers had to manually apply discounts in Vantage to approximate their actual costs. The new integration (released in July 2025) uses the Databricks system tables and provides more accurate, granular cost data. Switching to this integration ensures your cloud cost data in Vantage is more complete, accurate, and reflective of your negotiated Databricks pricing. Vantage recommends you perform the new integration to receive the most up-to-date billing data from Databricks, as new products will not be added to the former billable usage logs.What You Need to Know Before Migrating
Data availability for the new integration depends on:- Your Databricks account’s creation date
- When system tables were enabled
- How long the data has been retained in your account
- Backfill your new Databricks Vantage integration as far back as the Databricks system tables contain data
- Remove any overlapping data from your old Databricks Vantage integration
How to Migrate from the v1 Integration to v2
This integration guide provides the steps for migrating from v1 to v2. Keep your v1 integration active while you set up and validate v2, then disable the v1 log delivery after confirming that v2 data is available and accurate.Step 1 - Set Up the v2 Integration
Create a new Databricks integration while your v1 integration remains active. Use one of the following setup methods:Manually via your Databricks account
Using a Terraform module
Step 2 - Validate v2 Data
After clicking Connect Account, you will see the status of your v2 integration change to Importing within the Vantage console. Vantage will load the previous six months of Databricks usage data. As soon as costs are processed, they will be available on your All Resources Cost Report. Before disabling v1 log delivery, validate the new integration:- Wait for the v2 integration to finish importing and change to Stable.
- Compare recent month totals between your v1 and v2 Databricks costs.
- If you had manually applied discounts on v1, verify that v2 reflects your negotiated pricing from
system.billing.account_prices. - Confirm that Cost Reports, saved filters, Virtual Tags, dashboards, and alerts using Databricks costs still behave as expected.
Step 3 - Disable v1 Billable Usage Log Delivery
After v2 is validated, disable the Databricks log delivery configuration that sends v1 billable usage logs to Vantage.1
Configure the Databricks CLI for account-level authentication. Follow the user-to-machine authentication guide to ensure you have valid credentials.
The commands below assume you have followed Databricks’s instructions and have account-level access. Be sure to use the profile that corresponds with your Databricks account administrator.
2
Disable the log delivery configuration named
vantage-billable-usage-delivery using its config_id.Click to view an example log delivery
Click to view an example log delivery
Step 4 - Remove or Retain the v1 Integration in Vantage
To view your v1 Databricks integration in Vantage, navigate to the Integrations page. The integration is displayed with the labelV1 - Read Only, and you’ll be unable to make updates to that integration in Vantage.
If you need to update any manually applied Databricks discounts on a v1 integration, contact support@vantage.sh.

Step 5 - Manage Workspace Access
Once the v2 import is complete and the integration status changes to Stable, you can select which workspaces this integration is associated with. See the Workspaces documentation for information.Data Refresh
See the provider data refresh documentation for information on when data for each provider refreshes in Vantage.Databricks Reporting Dimensions
On Databricks Cost Reports, you can filter across several dimensions:- Billing Account (e.g., Organization)
- Linked Account (e.g., Workspace)
- Service (e.g., Jobs Compute)
- Charge Type (e.g., Usage)
- Category (e.g., Photon)
- Subcategory (e.g., Serverless)
- Resource ID (specific ID for a given Databricks resource)
- Tags (Tags from Databricks, see section below, and Virtual Tags created in Vantage)
Databricks Tags
The Tag filter contains values like job_id, which can be used to view costs for specific Databricks jobs. Vantage gets tags fromidentity_metadata, usage_metadata, and custom_tags from system.billing.usage; workspace_name from system.access.workspaces_latest; cluster_name, tags, and driver_instance_pool_id from system.compute.clusters; and warehouse_channel, warehouse_type, warehouse_name from system.compute.warehouses. Below is a list of tags Vantage ingests.
Access Vantage via Databricks MCP Catalog
The Vantage MCP is available in the Databricks Marketplace and Model Context Protocol (MCP) Catalog, which makes it easy to integrate cloud cost intelligence directly into your Databricks AI workflows.With the Vantage MCP integration, you can:
- Gain unified visibility into Databricks costs alongside AWS, Azure, GCP, and other cloud services
- Analyze cost drivers, usage patterns, and trends with automated reporting and FinOps insights
- Apply Virtual Tags in Vantage to allocate Databricks costs by team, environment, or business unit and ask questions about how these costs are allocated
Review the Databricks documentation for information on how to use MCP servers in Databricks. You need an active Vantage account with a Databricks integration (follow the instructions above). You also need a Vantage API key to use as your bearer token.
1
Log in to the Databricks console, and navigate to the Databricks Marketplace.
2
Use the Product filter to filter by MCP servers.
3
Select Vantage and click Install.
4
Enter a Connection name, your Vantage token, and accept the provided terms.
5
Click Install.